Attention: For the english version, click here!
ugrep und grep sind beides Tools für die Kommandozeile und helfen dabei Texte zu durchsuchen. Grep steht hierbei für global regular expression print. Das „U“ bei ugrep hat keine feste Bedeutung. Um den Entwickler zu zitieren: „U name it„. Ob user friendly, ultra, universal… alles ist irgendwie zutreffend
Während grep das allzeit beliebte Standardtool unter UNIX/Linux-Systemen unter Entwickler oder Systemadministratoren ist, bietet ugrep eine weitaus größeres Reportoire an Funktionalität. Beide Tools sind jedoch im Kern gleich. Sie durchsuchen eine Datei und liefern die Zeile zurück in der das gesuchte Wort oder Zeichen gefunden wurde. Doch worin unterscheiden sich die beiden Tools? Das möchte ich jetzt zeigen.
Installation von ugrep
Wer ugrep noch nicht auf seinem System hat, dem gebe ich hier ein paar Installationsanweisungen für die gängigen Systeme:
- Windows: Hier herunterladen
- FreeBSD: pkg install ugrep
- MacOS: brew install ugrep
- Linux: apt install ugrep
Das offizielle Repository findet ihr hier: https://github.com/Genivia/ugrep/
ugrep vs. grep
Wie bereits erwähnt, durchsucht grep Dateien zeilenweise und gibt alle Zeilen zurück, die mit der Suchanfrage übereinstimmen. Es ist ein sehr nützliches Werkzeug, aber es hat auch einige Einschränkungen. Zum Beispiel kann grep nur ASCII-Textdateien durchsuchen und kann keine regulären Ausdrücke in Unicode-Texten verarbeiten. Es kann auch manchmal langsam sein, wenn es mit sehr großen Dateien oder vielen Dateien arbeitet.
ugrep hingegen ist ein modernes, leistungsstarkes Tool, das diese Einschränkungen überwindet. Einige der wichtigsten Unterschiede sind:
- Unicode-Unterstützung: ugrep kann Texte in verschiedenen Sprachen, einschließlich Unicode, durchsuchen. Es erkennt automatisch die Kodierung der Datei und sucht entsprechend danach.
- Reguläre Ausdrücke: ugrep bietet eine erweiterte Unterstützung für reguläre Ausdrücke, einschließlich POSIX, Perl und PCRE. Dies ermöglicht eine genauere Suche und Filterung von Texten.
- Geschwindigkeit: ugrep ist schneller als grep, insbesondere wenn es um die Suche in großen Dateien oder vielen Dateien geht. Es verwendet Multithreading und andere Optimierungen, um die Leistung zu maximieren.
- Flexibilität: ugrep bietet viele Optionen und Schalter, die die Suche und das Ergebnis anpassen können. Zum Beispiel können Sie die Suche auf bestimmte Dateitypen oder Verzeichnisse beschränken oder das Ergebnis auf bestimmte Felder beschränken.
Laufzeittest im Vergleich
Für mich ist es, bei einem solchen Vergleich, wichtig ein greifbares Ergebnis zu liefern. Deshalb habe ich an der Stelle eine Testdatei mit 10 Millionen Zeilen Text erstellt, die zufällige Zeichen enthalten. Die Dateigröße beträgt etwa 95 MB.
Um die Laufzeit von grep und ugrep zu vergleichen, habe ich die Zeit gemessen, die jeder Befehl benötigt, um alle Zeilen zu finden, die das Wort „lorem“ enthalten. Ich habe dies auf meinem frisch installierten Test-Client mit FreeBSD durchgeführt. Hardware ist ein Intel Core i7-Prozessor und 16 GB RAM.
Das Ergebnis war wie folgt:
- grep: 4,56 Sekunden
- ugrep: 0,70 Sekunden
Der Sieger ist hier eindeutig. Doch in manchen Fällen ist auch grep der Sieger. Es ist wichtig zu beachten, dass die Laufzeit von ugrep von vielen Faktoren abhängt, wie der Größe der Datei, der Art des Texts, der Suchanfrage usw. In einigen Fällen kann grep schneller sein als ugrep, insbesondere bei kleineren Dateien. Wem es hier wirklich um Sekunden geht, der sollte je nach Anwendung, einen eigenen Test durchführen.
Beispiele
Jetzt haben wir in der Theorie schon gelernt, was ugrep zu bieten hat und woring die Stärken liegen. Nachfolgend möchte ich euch ein paar Fallbeispiele zeigen, in denen ugrep definitiv punktet.
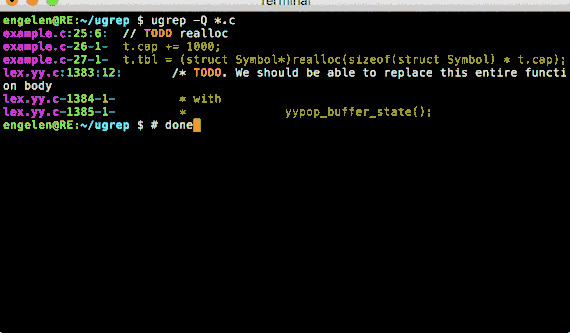
Folgender Befehl öffnet ein UI (user interface), in der man die Möglichkeit hat Suchmuster einzugeben und in den Ergebnissen zu navigieren. Die Option „-Q“ steht für „quick search“. Die Funktion ist besonders nützlich für Anwender, die nicht so erfahren im Umgang mit der Kommandozeile sind oder für diejenigen, die einfach eine benutzerfreundlichere Oberfläche bevorzugen.
ugrep -QSuche nach einem Wort in einer bestimmten Datei:
ugrep "word" file.txtSuche nach einem Wort in allen Dateien in einem Verzeichnis:
ugrep "word" directory/Suche nach einem Wort in allen Dateien mit einer bestimmten Erweiterung:
ugrep "word" *.txtSuche nach einem Wort in allen komprimierten Dateien in einem Verzeichnis:
ugrep -z "word" directory/Suche nach einem Wort und zeige den Kontext in der Ausgabe:
ugrep -C 3 "word" file.txtDas sind nur ein paar sehr einfache Beispiele. Der wahre Umfang zeigt sich beim Durchlesen der man page:
man ugrepInnerhalb der oben angesprochenen UI, kannst du die Hilfe, indem du F1 oder CTRL-Z betätigst.
Zusammenfassung
Für den Fall, dass du ugrep noch nicht kanntest, hoffe ich, dass dieser Beitrag nützlich für dich war. Wenn du wirklich viel mit großen Dateien in allen Variationen arbeitest, kann dir ugrep definitiv dein Alltag vereinfachen. Wie so oft im Leben, kommt es hierbei immer auf den Anwendungsfall an. Ansonsten hast du eben was Neues gelernt, das kann nie schaden. Viel Spaß beim Experimentieren!
ugrep vs. grep – What are the differences?
ugrep and grep are both command-line tools that help search for text in files. Grep stands for „global regular expression print“, while the „U“ in ugrep has no fixed meaning, as the developer stated, „U name it„. Whether it stands for user friendly, ultra, or universal, all of these interpretations are somehow fitting.
While grep is the all time favorite standard tool among developers or system administrators on UNIX/Linux systems, ugrep offers a much wider range of functionality. However, both tools are fundamentally the same. They search a file and return the line in which the searched word or character was found. So, what are the differences between the two tools? Let’s find out.
Installation of ugrep
For those who do not have ugrep on their system yet, here are some installation instructions for common systems:
- Windows: Download it here
- FreeBSD: pkg install ugrep
- MacOS: brew install ugrep
- Linux: apt install ugrep
The official repository can be found here: https://github.com/Genivia/ugrep/
As mentioned before, grep searches files line by line and returns all lines that match the search query. It is a very useful tool, but it also has some limitations. For example, grep can only search ASCII text files and cannot process regular expressions in Unicode text. It can also sometimes be slow when working with very large files or many files.
ugrep, on the other hand, is a modern, powerful tool that overcomes these limitations. Some of the key differences are:
ugrep vs. grep
- Unicode support: ugrep can search texts in different languages, including Unicode. It automatically detects the file’s encoding and searches accordingly.
- Regular expressions: ugrep provides advanced support for regular expressions, including POSIX, Perl, and PCRE. This allows for more precise searching and filtering of texts.
- Speed: ugrep is faster than grep, especially when searching in large files or many files. It uses multithreading and other optimizations to maximize performance.
- Flexibility: ugrep offers many options and switches that can customize the search and results. For example, you can restrict the search to specific file types or directories or limit the result to specific fields.
Runtime comparison test
For me, when conducting such a comparison, it is important to provide a tangible result. Therefore, I created a test file with 10 million lines of randomly generated text containing various characters. The file size is approximately 95 MB.
To compare the runtime of grep and ugrep, I measured the time each command took to find all the lines containing the word „byte„. I performed this test on my freshly installed FreeBSD test client, which has an Intel Core i7 processor and 16 GB of RAM.
The results were as follows:
grep: 4.56 seconds
ugrep: 0.70 seconds
The winner is clearly ugrep in this case. However, in some cases, grep may be faster than ugrep, especially when dealing with smaller files. It is important to note that the runtime of ugrep depends on many factors, such as file size, text type, search query, etc. If speed is critical, it is recommended to conduct your own tests depending on the application.
Examples
Now that we have learned about what ugrep has to offer and where its strengths lie, I would like to provide some use cases where ugrep definitely shines.
The following command opens a user interface where you have the ability to enter search patterns and navigate through the results. The option „-Q“ stands for „quick search“. This feature is especially useful for users who are not as experienced in using the command line or for those who simply prefer a more user-friendly interface.
ugrep -QSearch for a word in a specific file:
ugrep "word" file.txtSearch for a word in all files in a directory:
ugrep "word" directory/Search for a word in all files with a specific extension:
ugrep "word" *.txtSearch for a word in all compressed files in a directory:
ugrep -z "word" directory/Search for a word and display the context in the output:
ugrep -C 3 "word" file.txtThese are just a few very basic examples. The true scope is revealed when reading the man page:
man ugrepWithin the aforementioned UI, you can access help by pressing F1 or CTRL-Z.
Summary
In case you didn’t know about ugrep yet, I hope this post was useful for you. If you work a lot with large files in all kinds of variations, ugrep can definitely simplify your daily routine. As so often in life, it always depends on the use case. Otherwise, you have just learned something new, which can never hurt. Have fun experimenting!
Start the discussion